Chapter 3 Methods
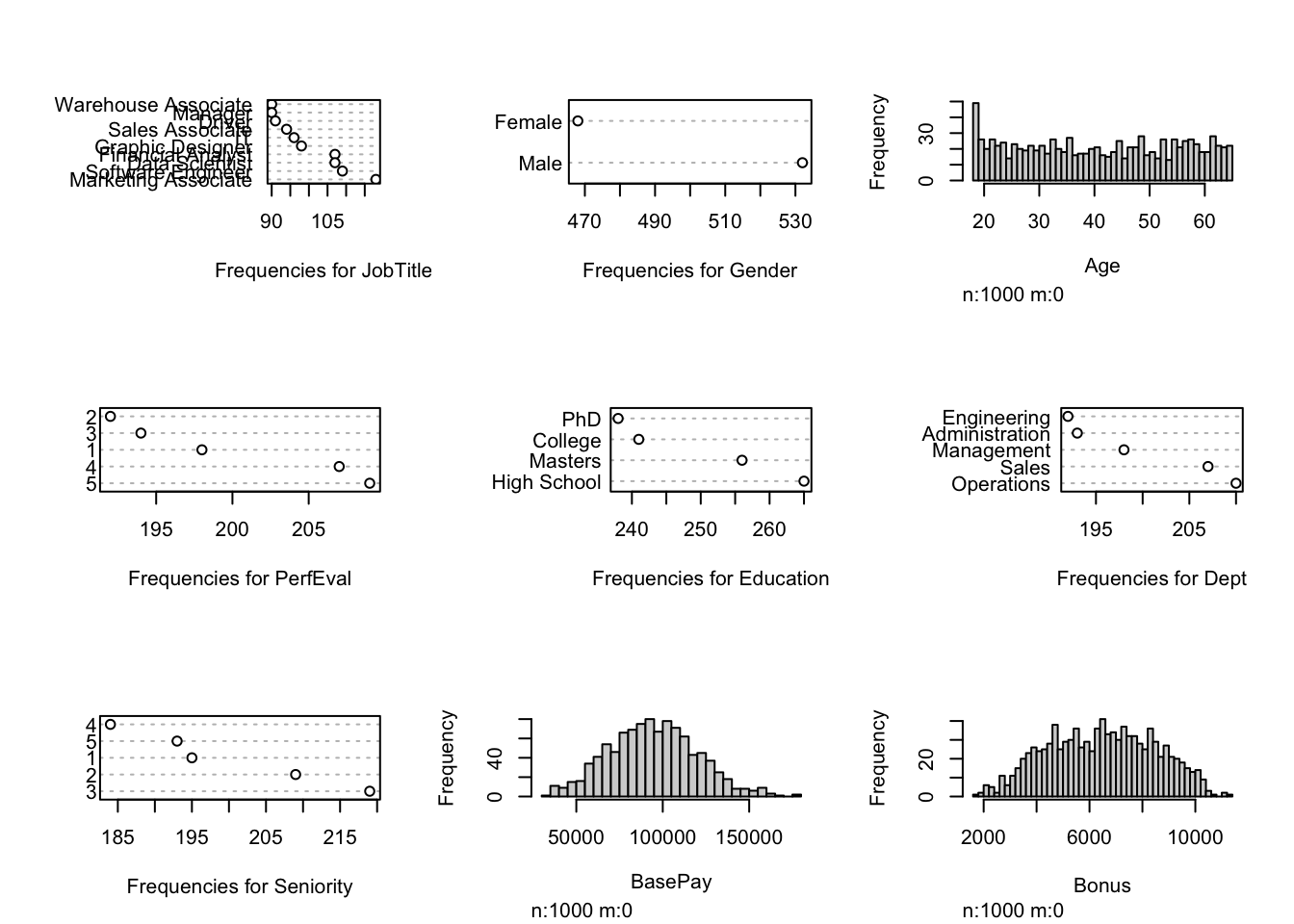
- Visualization of the original dataset:
3.1 Generating Missing Values
Before we perform the different methods of imputation for missing values we must first explore the types of missing data. These are: MCAR, MAR, MNAR.
MCAR (Missing Completely at Random) is the data missing where data points are not related to each other and probability of missing data is equal for every data point. This allows data to be unbiased and can use methods such as complete case analysis, single, and multiple imputation for valid analysis.
MAR (Missing at Random) is the likelihood of a value to be missing depends on other observed variables. This leaves a bias in our dataset and for this data type multiple imputation is a valid analysis.
MNAR (Missing Not at Random) is unequal and unknown probability to be missing for a dataset. Not only is the data missing but we cannot categorize data properly or know what data we do not have. For this data type, sensitivity analysis should be used.
Once missing value data type is determined some of the strategies are complete case analysis, single imputation, and multiple imputation.
Complete case analysis drops observations with missing values from the dataset. Single imputation replaces missing values with values thought to best represent the mechanism of the missing data such as mean or median.
Multiple imputation has several steps which summarize as imputation of multiple copies of original dataset are generated, replace missing values randomly sampled from the predictive distribution, fit models for each imputed dataset and perform statistical analysis on said datasets followed by pooling the results together. The result will contain the variability and uncertainty as if taken from a complete dataset without missing data and without introduction of bias.
Due to the challenge of missing data having many assumptions, decisions, and methods used for analysis, it is extremely important to thoroughly report each. Reporting the strategy used for missing data is critical for other researchers to reproduce and validate findings. Report findings such as count or proportion of missing values to variable of interest, methodology used for incomplete data analysis, assumptions regarding the cause of missingness: MCAR, MAR, or MNAR, software used to handle missing data, changes made, etc.
It is important to understand why and how to handle missing data. While multiple imputation is a preferred method to handle missing data in general, we still need to know when, why, and how. Detailed reporting is also needed to ensure reproducibility and validity.
Methods and ideas discussed will help deal with missing data in scientific research but should be considered as an introduction to the topic. This report will be focused on single and multiple imputation methods.
Generated NA’s for MCAR Type
Generated NA’s for MAR Type

Generated NA’s for MNAR Type

3.2 Single Imputation
3.2.1 Most Frequent for Categorical
The next imputation method that was performed is another form of single imputation which is most frequent imputation. This method is used for categorical variables and is considered another quick and simple approach for missing values. This method replaces missing values with the most frequent value (mode) of the variable, with zeros or a constant pre-defined value. Even though this is a very easy approach, this method also does not factor correlations between variables and can introduce bias to the dataset.
3.2.2 Mean for Continuous
The first imputation method performed will be single imputation but for continuous variables. This method consists of replacing the missing values with either the mean or median for continuous variables. This method is a very quick and simple approach when dealing with missing values. However, it does not factor correlations between variables and does not work for categorical variables.
3.3 kNN Imputation
KNN was the next imputation method performed. This method makes predictions about missing values by finding the K’s closest neighbors and impute the value based on the neighborhood. The procedure of the algorithm consists of creating a basic mean impute to construct a KDTree. The KDTree is used to compute the nearest neighbor and then it finds the average of KNN’s. This method has the advantage of being more accurate, but it is computationally expensive and is very sensitive to outliers.
3.4 Random Forest Imputation
The next method used is Random Forest. This package used (missForest) is an iterative imputation method based on a random forest allows quality and flexibility utilizing built-in out-of-bag error estimates. This non parametric alternative is also used on mixed types of data with ability to account for high-dimensions and different types of variables simultaneously.
3.5 MICE Imputatuion
The last method used is MICE (Multivariate Imputation by Chained Equations). This method involves filling the missing values multiple times until a certain threshold is met. An important assumption of the MICE method is that it assumes that the missing data is Missing At Random (MAR). This means that the probability that a value is missing depends only on observed values and not on unobserved values. A drawback occurs when the data is not MAR, it could result in biased estimates. By default, linear regression is used to predict continuous missing values. Logistic regression is used for categorical missing values. While MICE offers flexibility and solutions to the missing data problem, a number of complexities such as clustered and longitudinal data still present problems for which MICE may not be suited for.
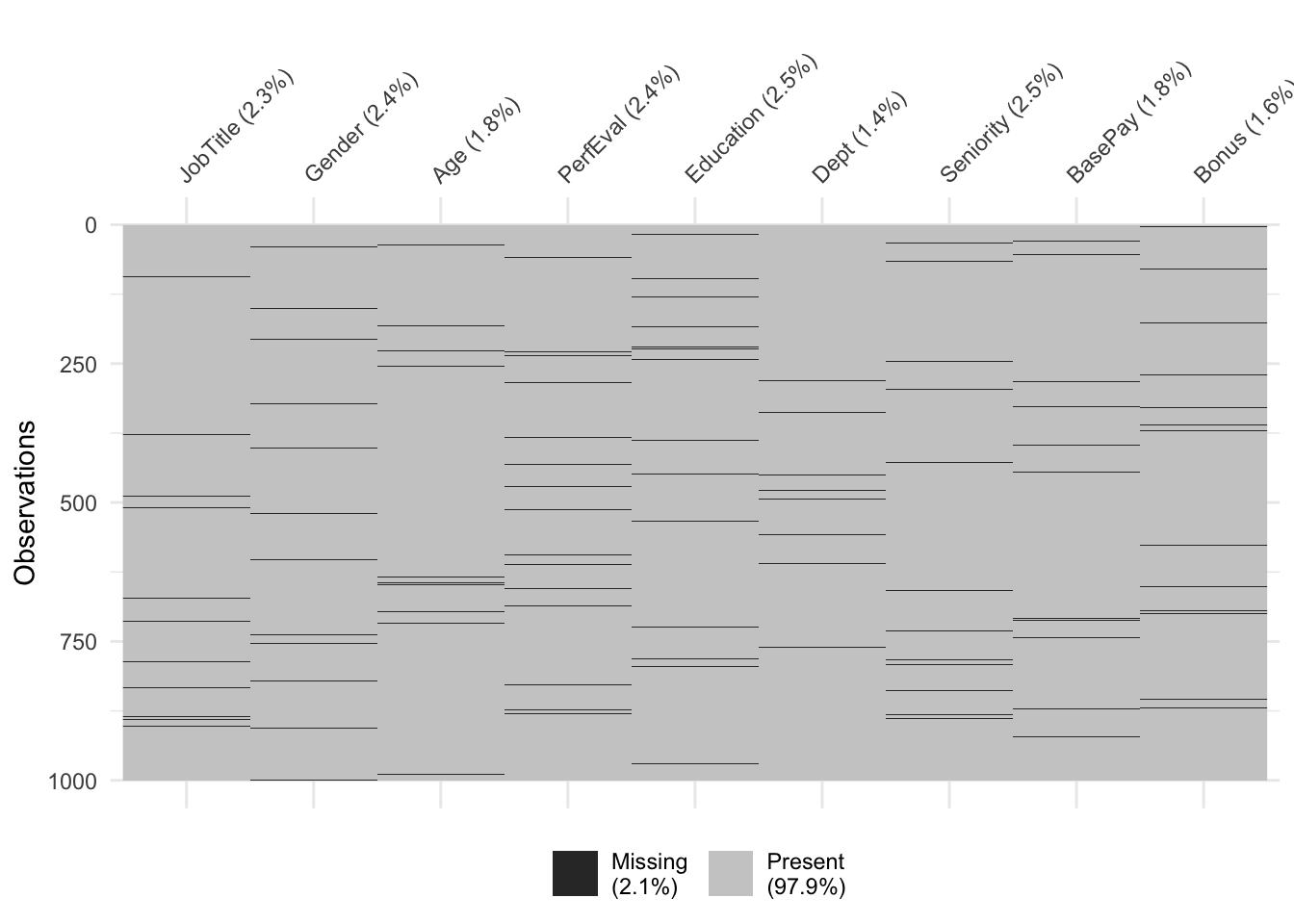
Visualization after performing SI to the original dataset:
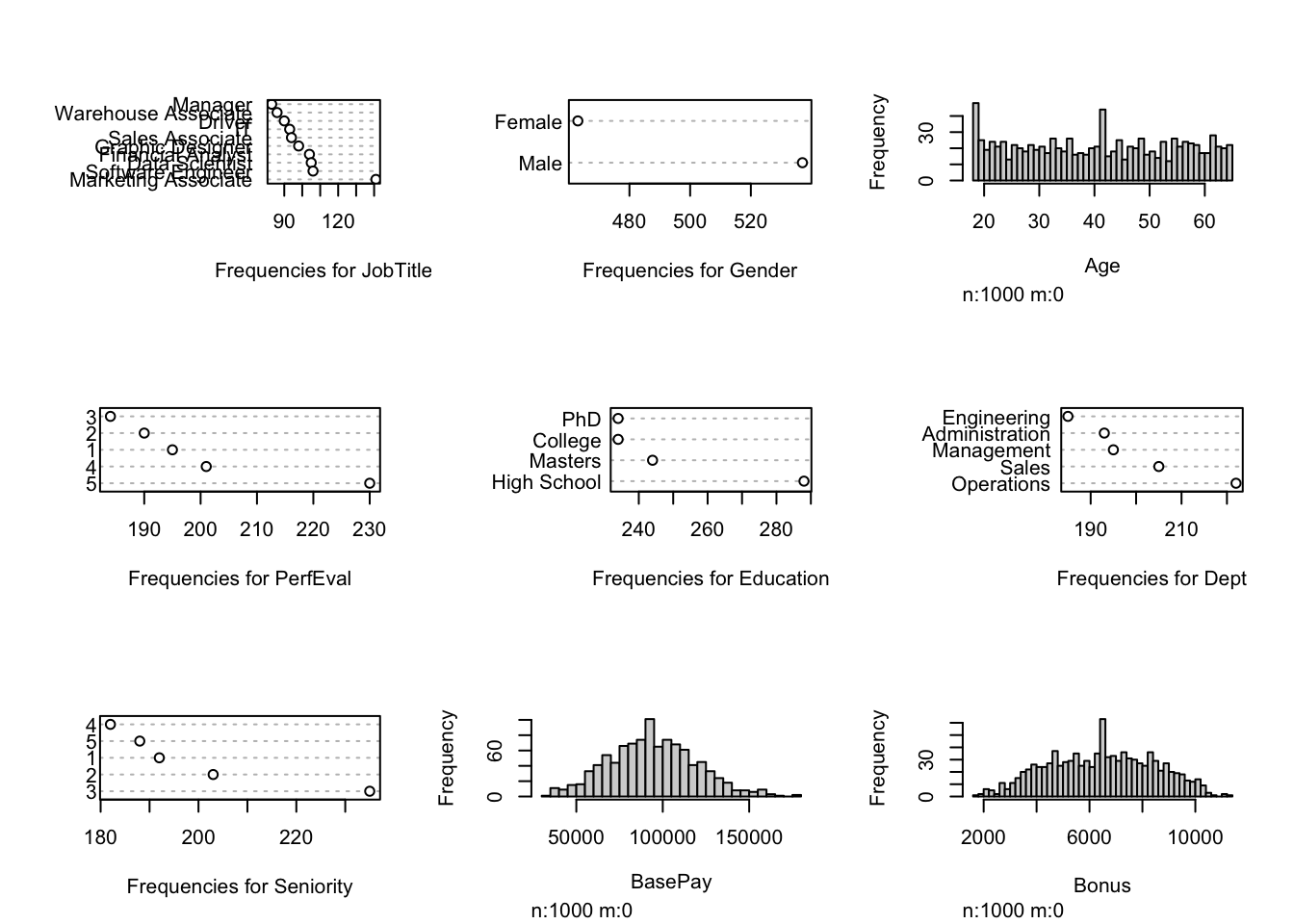
Visualization after performing MICE to the original dataset:
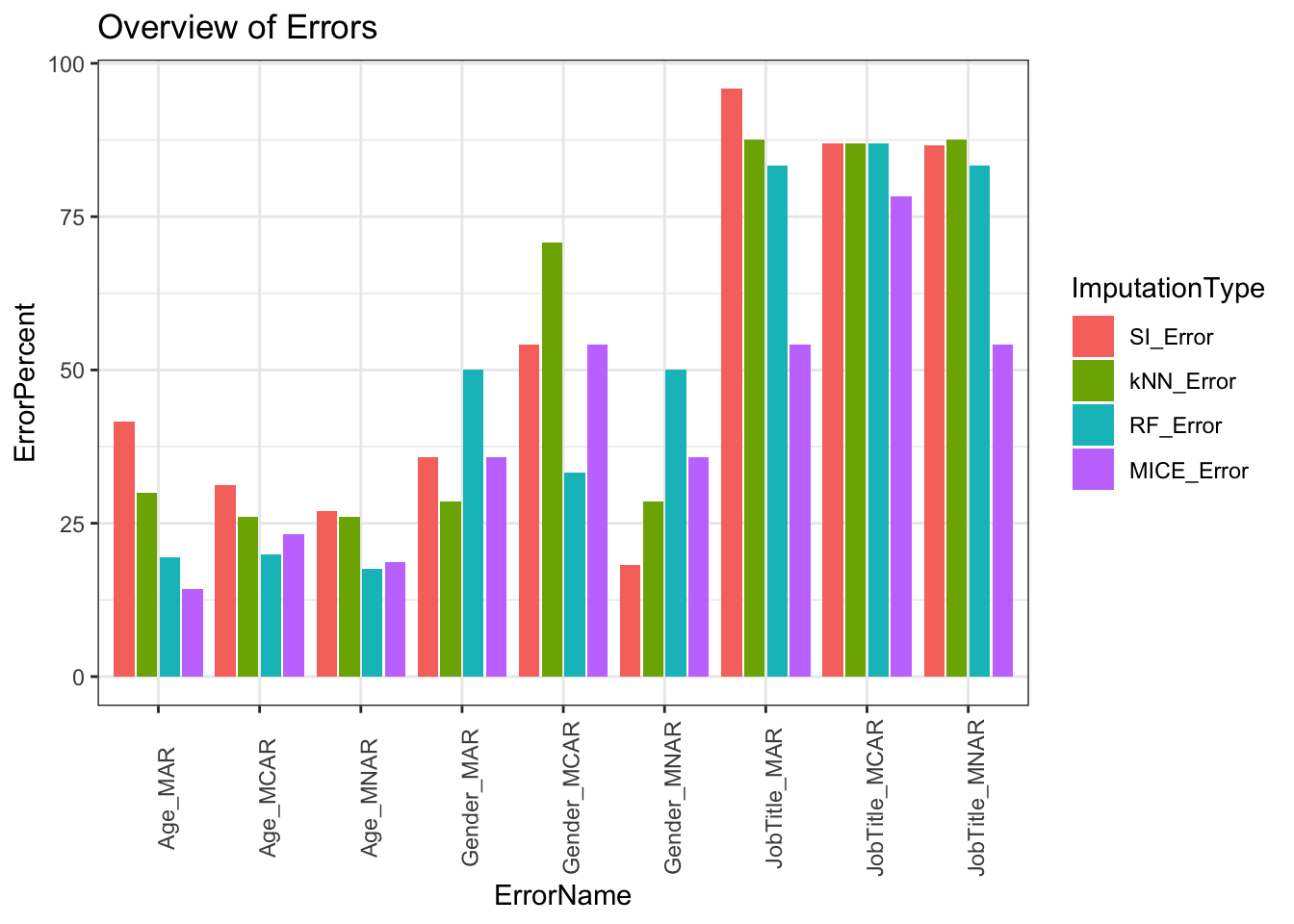
3.6 Results
3.6.2 Comparisons and Interpretation
Overview
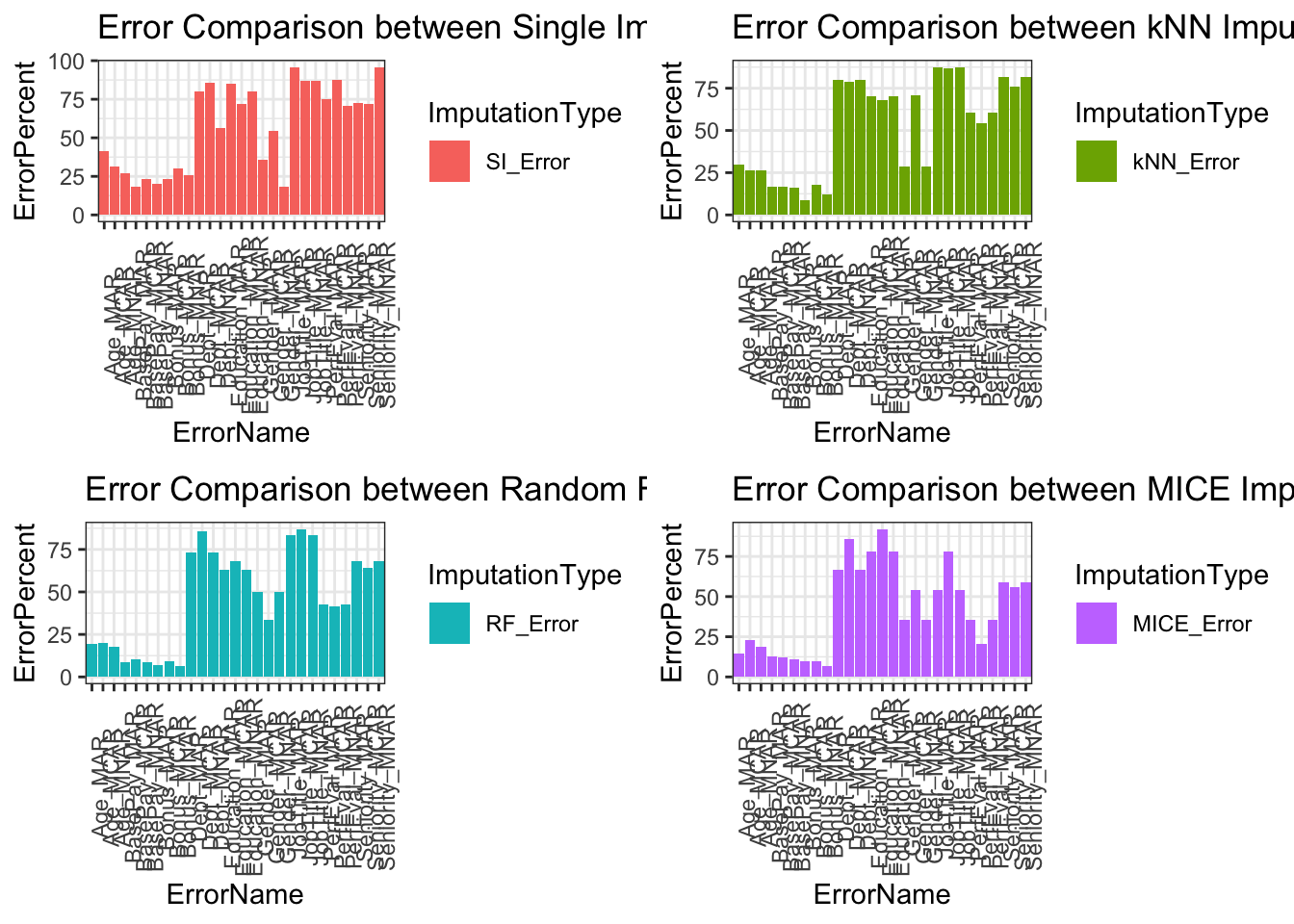
Our overall results show we have less error for continuous data than binary, nominal, and ordinal categorical data. Our best performing imputation method is MICE and our worst performing method is single imputation. Single imputation is expected to have high error because the method itself creates inaccuracies by not addressing variability in its imputation. In larger datasets single imputation or complete case scenarios will drastically change results in analysis and should be avoided. Other imputation methods such as kNN and RF performed competitively with slightly greater error than MICE. Most of our imputation methods have been designed to handle MAR data therefore, this data type had lower error than its counterparts MCAR and MNAR.
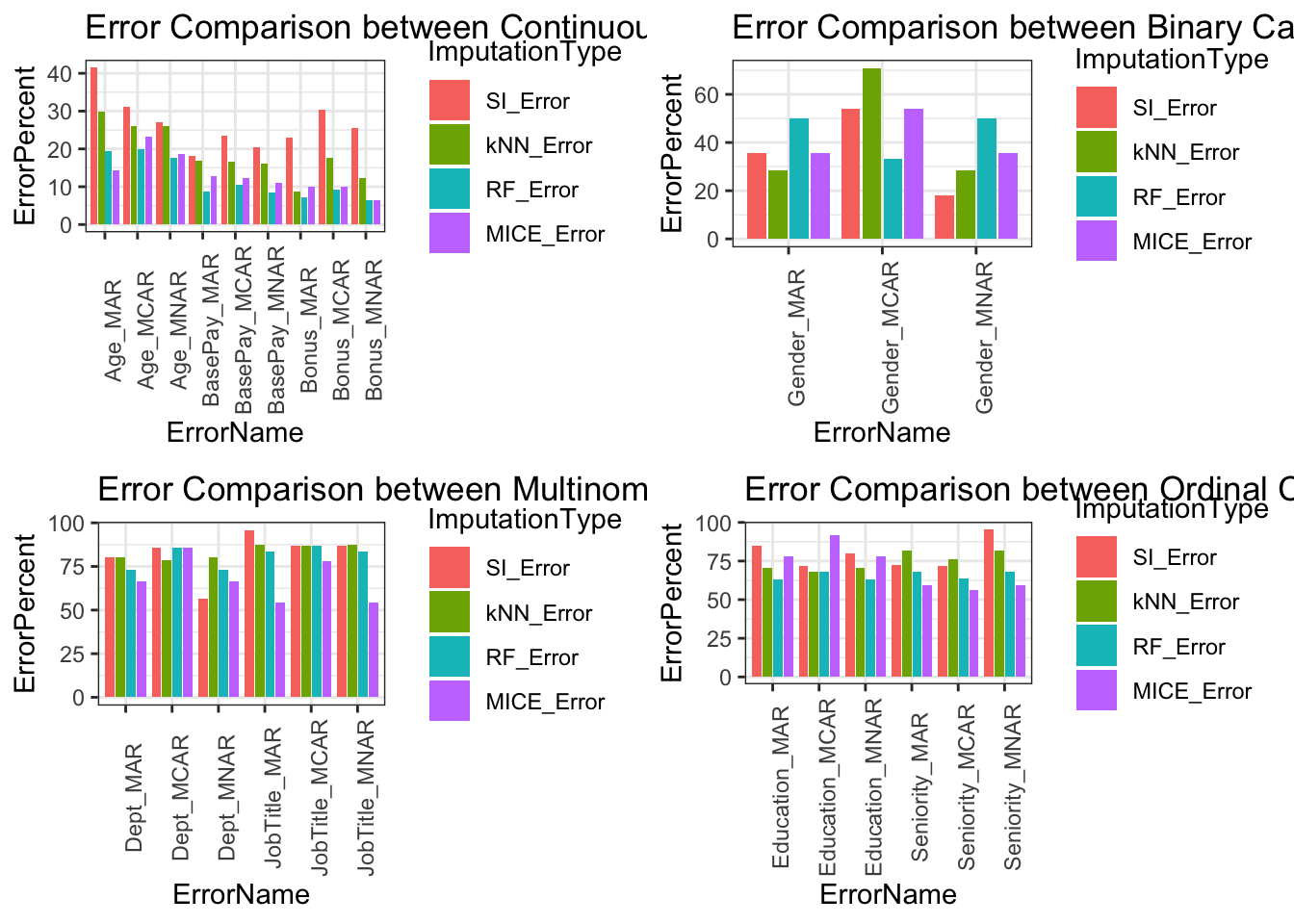
Error Comparison Between Data Types
Comparisons below showcase the imputation types with respect to variable types. Upper limit of errors for continuous variables is 40%, binary categorical variables is 60%, multinomial categorical variables is 100%, and ordinal categorical variables is 95%. Categorical variables error is higher because variability is based on frequency of occurrence in our data. Within larger datasets this error will drop because each miss classification has less impact on total error assuming the missing data type is MAR.
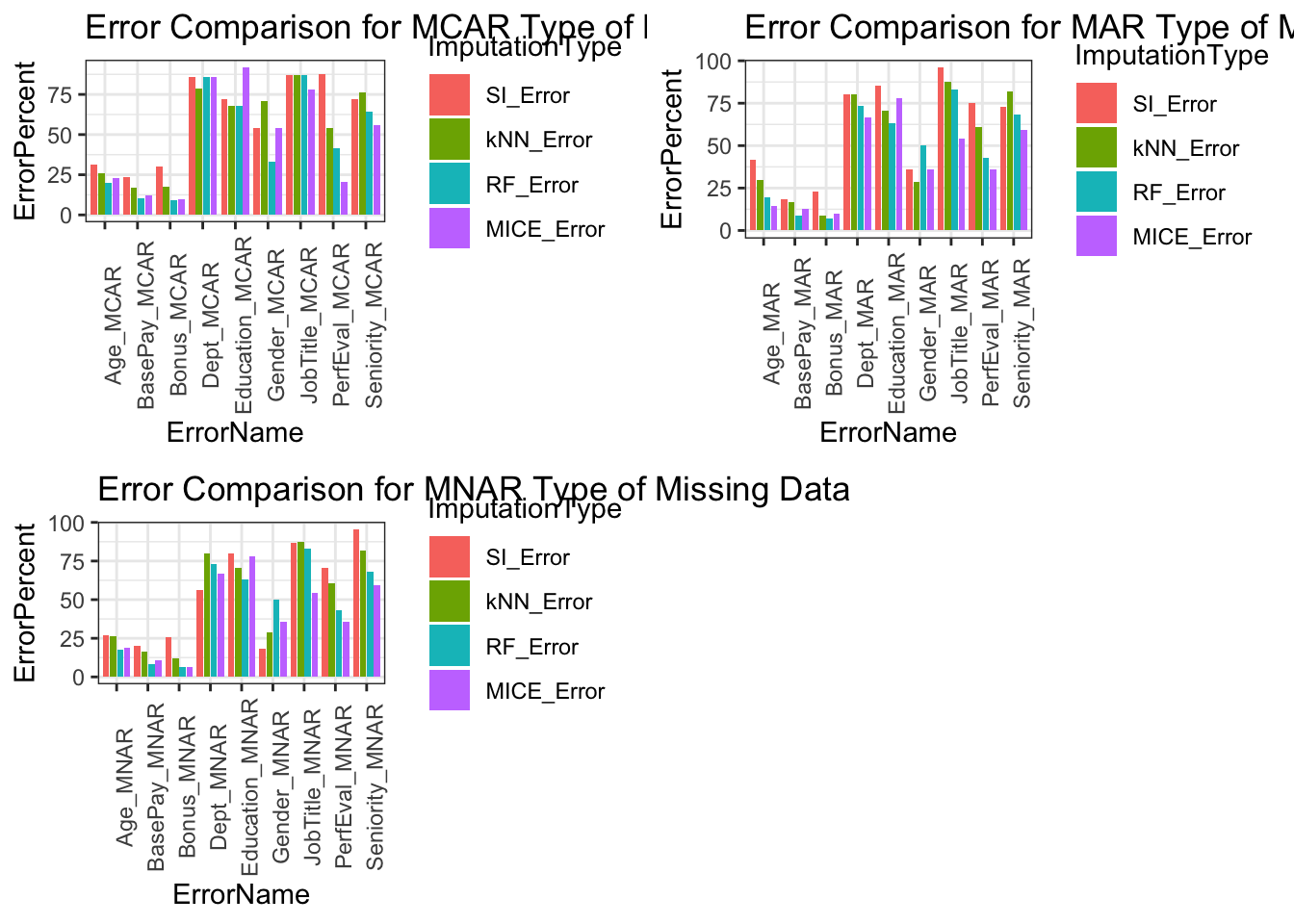
Error Comparison Between Types of Missing Data
We expected for our MAR type of missing data to be the best performer in terms of least amount of error percent however, because of the smaller size of our dataset, it is not as effective as it would be for a larger dataset. Given a larger dataset the differences between our missing data types is more easily compared. The methods of imputation are designed for MAR type of missing data. MCAR missing type of data is somewhat unrealistic because you would be omitting variables without relationships to the result.
Error Comparison Between Imputation Methods
Error comparisons between imputation methods shows MICE being the overall best method of imputation across majority of variables and missing data types. Single imputation is the worst method across the variables and missing data types. Both kNN and RF imputation performed similarly with RF having an edge across variable types. For imputation methods, further considerations are needed such as size of dataset, computation cost, time, dataset variable distribution, and ease of implementation.